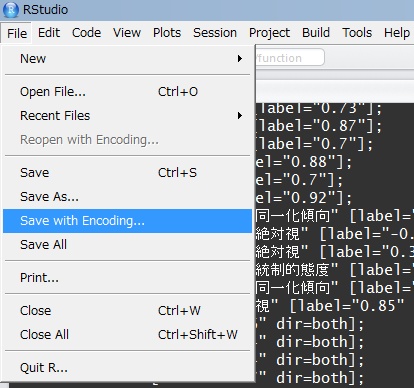
test1.mdl <- specifyModel()
文系学力 -> 国語, p1, NA
文系学力 -> 地理, p2, NA
文系学力 -> 英語, p3, NA
理系学力 -> 数学, p4, NA
理系学力 -> 化学, p5, NA
理系学力 -> 物理, p6, NA
文系学力 <-> 文系学力, NA, 1
理系学力 <-> 理系学力, NA, 1
文系学力 <-> 理系学力, c1, NA
国語 <-> 国語, e1, NA
地理 <-> 地理, e2, NA
英語 <-> 英語, e3, NA
数学 <-> 数学, e4, NA
化学 <-> 化学, e5, NA
物理 <-> 物理, e6, NA
summary(test1.sem <- sem(test1.mdl, S=cor(test), N=nrow(test)))
pathDiagram(test1.sem,ignore.double=FALSE, rank.dir="TB",
same.rank="文系学力,理系学力",
standardized = TRUE,
node.font=c("IPAGothic",12), edge.labels="values")
文系学力 -> 国語, p1, NA
文系学力 -> 地理, p2, NA
文系学力 -> 英語, p3, NA
理系学力 -> 数学, p4, NA
理系学力 -> 化学, p5, NA
理系学力 -> 物理, p6, NA
文系学力 <-> 文系学力, NA, 1
理系学力 <-> 理系学力, NA, 1
文系学力 <-> 理系学力, c1, NA
国語 <-> 国語, e1, NA
地理 <-> 地理, e2, NA
英語 <-> 英語, e3, NA
数学 <-> 数学, e4, NA
化学 <-> 化学, e5, NA
物理 <-> 物理, e6, NA
summary(test1.sem <- sem(test1.mdl, S=cor(test), N=nrow(test)))
pathDiagram(test1.sem,ignore.double=FALSE, rank.dir="TB",
same.rank="文系学力,理系学力",
standardized = TRUE,
node.font=c("IPAGothic",12), edge.labels="values")
今回はsem()関数には相関行列を使いました。
パス図も描いてみました。edge.labels="names"のdotファイルを示します。
digraph "test1.sem" {
rankdir=TB;
size="8,8";
node [fontname="IPAGothic" fontsize=12 shape=box];
edge [fontname="Helvetica" fontsize=10];
center=1;
{rank=same "文系学力" "理系学力"}
"文系学力" [shape=ellipse]
"理系学力" [shape=ellipse]
"文系学力" -> "国語" [label="p1"];
"文系学力" -> "地理" [label="p2"];
"文系学力" -> "英語" [label="p3"];
"理系学力" -> "数学" [label="p4"];
"理系学力" -> "化学" [label="p5"];
"理系学力" -> "物理" [label="p6"];
"文系学力" -> "文系学力" [label="" dir=both];
"理系学力" -> "理系学力" [label="" dir=both];
"文系学力" -> "理系学力" [label="c1" dir=both];
"国語" -> "国語" [label="e1" dir=both];
"地理" -> "地理" [label="e2" dir=both];
"英語" -> "英語" [label="e3" dir=both];
"数学" -> "数学" [label="e4" dir=both];
"化学" -> "化学" [label="e5" dir=both];
"物理" -> "物理" [label="e6" dir=both];
}
rankdir=TB;
size="8,8";
node [fontname="IPAGothic" fontsize=12 shape=box];
edge [fontname="Helvetica" fontsize=10];
center=1;
{rank=same "文系学力" "理系学力"}
"文系学力" [shape=ellipse]
"理系学力" [shape=ellipse]
"文系学力" -> "国語" [label="p1"];
"文系学力" -> "地理" [label="p2"];
"文系学力" -> "英語" [label="p3"];
"理系学力" -> "数学" [label="p4"];
"理系学力" -> "化学" [label="p5"];
"理系学力" -> "物理" [label="p6"];
"文系学力" -> "文系学力" [label="" dir=both];
"理系学力" -> "理系学力" [label="" dir=both];
"文系学力" -> "理系学力" [label="c1" dir=both];
"国語" -> "国語" [label="e1" dir=both];
"地理" -> "地理" [label="e2" dir=both];
"英語" -> "英語" [label="e3" dir=both];
"数学" -> "数学" [label="e4" dir=both];
"化学" -> "化学" [label="e5" dir=both];
"物理" -> "物理" [label="e6" dir=both];
}